DDD compared to CRUD
A CRUD application is a thin layer between the User and the Database and focuses on the Data and most of the Business Logic is not implemented.
DDD is Task-based and focuses on the Business Logic and the intents of the User.
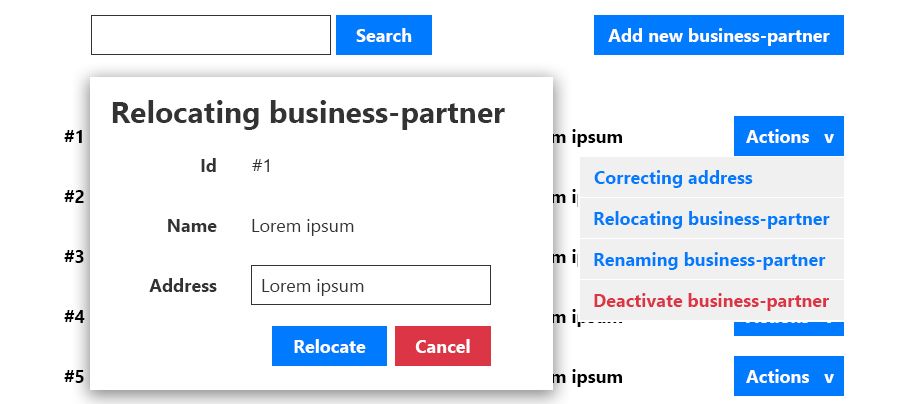
CRUD applications usually do not differentiate between intentions usually they are just "Changing an Address".
DDD distinguishes between intentions, “Correcting an Address” and “Relocating the Customer” are different use-cases.
CRUD applications use a deductive UI which is easier to design:
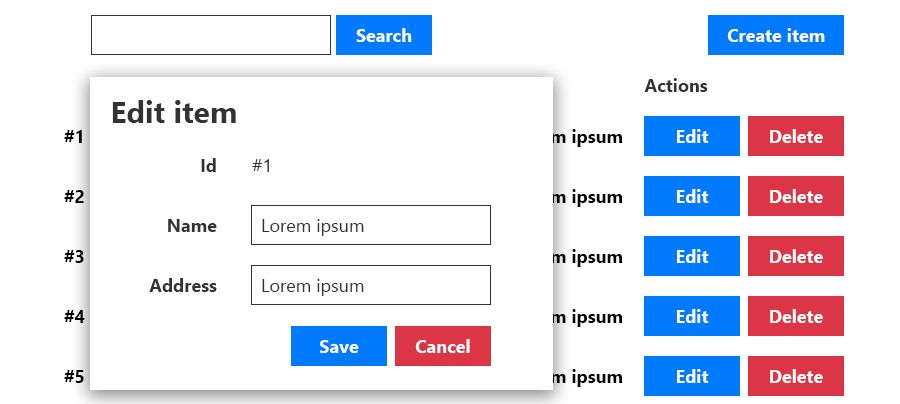
DDD uses an inductive Task-based-UI:
A CRUD application has the advantages:
- The Business Logic can change over time without changing the Application.
- CRUD generators can be used to produce code faster.
A DDD application has the advantages:
- There is no abstraction between the Domain logic and the way the Business works, therefore the knowledge belongs not only to the author developers. Business people and Technical people speak the same language.
- Users are guided through the Business processes, their deep knowledge is not necessary about the Application and the Business Rules. Data is expected to stay consistent, eventually consistent at least. New users has a gentle learning curve and can produce effective work early.
- Unlike CRUD, DDD respects OOP rules, separation of concerns through the whole application. Not tied to the Anemic Model, in most cases Rich Models should be used in the Domain. Supports writing decoupled code which helps to maintain the pace of the development. Changing the Application stays easy, works well with iterative and agile software development. Helps to deal with emerging and increasing complexity. Compatible with a lot of more advanced architectures.
- Can provide a lot of information about the efficiency of the business processes.
DDD is basically an attempt to reduce complexity.
Domain
Imagine that plain objects define how the business works (preferably without any technological determination). I.e. by data representations, internal relationships, business logic, etc.
Ubiquitous language
By the ubiquitous language things mean the very same for the Domain experts and for the Developers. There is no abstraction between the Domain logic and the way the Business works.
Bounded Context
A Bounded Context is a conceptual boundary around related classes.
DTO
In order to achieve better Separation of Concerns, and to avoid coupling we communicate with Data Transfer Objects instead of Model objects between our Bounded Contexts and outward of the Core Domain.
Architectural Styles
DDD is not tied to any particular architectural style.
- Procedural. The so-called spaghetti code.
- Layered Architecture to introduce maintainability and re-usability perspectives. Introduces a top Presentation and a bottom Infrastructure Layer above and below the Model Layer. Due to its highly coupled nature Layered Architecture is the less obvious spaghetti architecture.
- Hexagonal Architecture (Ports and Adapters) breaks up the application into inside and outside layers and communicates through Ports and Adapters to invert the Flow of Control. The default architecture to go when a little more complexity is expected. Hexagonal Architecture turns the Framework into a tool, just a dependency. Introduction to Hexagonal Architecture, A little more detail about Hexagonal Architecture
- Command Query Responsibility Segregation (CQRS) separates the Write (Command) and the Read (Query) Model. Each Bounded Context needs its own decisions, not an application wide solution. Recommended for situations when the complex business logic and the complex UI(s) are demanding very different Write Model and Read Model(s), and maybe there is a large difference between the number of reads and writes, and high availability is more important than real time consistency. The Write Model holds the true state, only returns "OK" or "KO". The Read Models are only Eventually Consistent and often synchronized by Events, usually by Projections. Projections are not a Cache, we are not regenerating Projections until anything changes. Every Read Model is lifted from domain concerns (maybe even lives on a different machine) and is only subject to the needs of the UI. Usually there is a one-to-one relationship between the Read database tables and UI views and an ORM is not needed anymore. Preferably parallel teams can work on each Model. CQRS allows a lot of flexibility because we are no longer bound by a single Model on which we i.e. have to run increasingly monstrous SQL queries. Separating the single model not only reduces but also adds a lot of complexity, and in case of just demanding queries we should consider applying a simple ReportingDatabase instead.
- Event Sourcing builds up the current state of the Aggregates from Snapshots and linear sequence of Events from an Eventstore. This architecture works great with scalable distributed systems, especially with SSDs which are not optimized for updates rather inserts, and works great with NoSQL databases since we only need one table. Works great with CQRS. Caution! :) Resolving certain bugs and errors are not trivial with Event Sourcing, especially in distributed systems.
MVC is not an architecture rather it is a delivery mechanism. The usual Symfony or Laravel MVC application is probably a Layered Architecture.
The Framework should be just a dependency of the Domain.
Folder structure
Imagine going into a public toilet and it turns out to be a library. Developers with fresh eyes need to recognize the current Architecture and what the application currently does on a high level based on only the folder structure and file names. Structuring our code is equally important as the chosen Architecture.
Screaming Architecture - Robert C. Martin
Structuring code with Hexagonal Architecture
Since the Domain is all about domain concerns and nothing technical I recommend to structure the Domain/ folder based on Domain concerns and nothing technical.
And since the Infrastructure is all about technical concerns I recommend to structure the Infrastructure/ folder based on Technical concerns.
src/
|---WorthReading/
|---Billing/
| |---Domain/
| | |---Bill/
| | |---Order/
| |
| |---Infrastructure/
| |---Logging/
| |---Persistence/
| |---Doctrine/
| |---Redis/
|
|---Cart/
| |---Domain/
| | |---OrderItem/
| | |---Adjustment/
| |
| |---Infrastructure/
| |---Logging/
| |---Persistence/
| |---Doctrine/
| |---Elasticsearch/
| |---Redis/
|
|---Catalog/
| |---Domain/
| | |---Product/
. . .
|
|---Inventory/
| |---Domain/
. .
Value Object
- replaceable
- immutable, replace them to change them
- measures, quantifies, describes something
- has no id
- its notion of equality is based on its state rather than its object identity
- it has a basic type behavior rather object like behavior from the memory point of view in PHP
- it can hold other Value Objects
- created by its constructor or when there is multiple way of creation by factory methods (self over static)
- fully encapsulate the behavior and data its holding
- side-effect free behavior
- fully testable
- i.e. id, money, date, color, postal address, quantity
The context decides if an object is an Entity or a Value Object. I.e. a postal address can be a Value Object because it can be anyone's postal address and we do not keep track of individual postal addresses. As a rule of thumb try to implement the objects in the Domain as Value Objects and only implement as an Entity if necessary.
Collection of Value Objects
Persisting Value Objects are easy except persisting a collection of Value Objects. Serializing their values is an option but it is not well searchable.
I consider Value Object Collections as Value Objects themselves. The complexity of dealing with Value Object Collections depends on the situation i.e. whether we want to conceal the collection in the Aggregate or not. Concealing things in a Rich Model can introduce some complexity which can be handled very well with Creational design patterns i.e. Factory, Builder.
Anemic vs Rich Domain Model
Anemic Domain Model
- The Domain Objects are only pure data structures.
- Services implement a Model’s domain logic.
Rich Domain Model
- The domain logic is implemented by the Domain Objects.
- Services contain only the domain logic which cannot be implemented in Domain Objects.
I.e. think about the Login process. Since the User model is not yet instantiated the login process should not be called on it.
However i.e. changing a User's name should be implemented in the User model because if we introduce i.e. a new "updatedAt" property to implement it correctly in an Anemic Model the developers would need to be fully aware of not just the whole business logic in every service and the whole application but also the parallel working teams daily work.
But what about the Single-responsibility principle (SRP)?
Every class in a computer program should have responsibility over a single part of that program's functionality, which it should encapsulate.
SRP depends on your definition of responsibility.
With the Anemic Domain Model we try to take apart the Domain Model in a way if the business logic changes the classes would have only one reason to change. This will result in multiple services which we need to keep consistent and eventually will lead to an inconsistent state. It is easy to fall into the trap of modeling a database table as a one-to-one object representation. A fully testable Anemic Domain Model is easier to implement but way harder to keep consistent.
With the Rich Domain Model we encapsulate the business logic in the Domain Object so it manipulates the underlying Value Objects which hold and encapsulate the object representations of database fields. I.e. the User's "email" property will be a Value Object which validates the min. and max. length and the correct format of the primitive email address value. The User's "changeEmail" method i.e. will not only update the "email" property but the "updatedAt" property too by a new Value Object and also publishes an "EmailChanged" Event. If the User's "changeEmail" method needs a service then inject the service through the method applying the Interface Segregation Principle (ISP) to keep everything testable.
Active Record vs Data Mapper
Active Record Data Access Layer
The goal of the pattern is to keep CRUD tasks simpler and quicker to implement.
- Couples the database design to the object representations.
- Collection, Inheritance, Association, Embeddable (Value Objects) are tricky to implement or cannot be.
- Can't work in complex applications.
Data Mapper Data Access Layer
The goal of the pattern is to keep the in memory representation and the persistent data store independent of each other and the data mapper itself.
- The database design and the object representations are decoupled following the Single Responsibility Principle.
- It is easy to implement Collections, Inheritance, Associations and Embeddables (Value Objects)
Doctrine is the most complete Data Mapper ORM for PHP.
Entity
- mutable, update them to change them
- has id
- it has object type behavior from the memory point of view in PHP
- it can hold other Entities and Value Objects
- created by its constructor or Factory or Repository
- fully testable
- i.e. person, order
Identity
The identity is represented as a primitive type or a Value Object, usually passed by a construct method argument.
Generated by:
- Client (i.e. ISBN for Publications)
- Application (i.e. a Repository's getNextIdentity() method usually a UUID)
Other Bounded Context or Persistence Mechanism generated Identity is not recommended. AUTOINCREMENT identifiers are fast to insert and fast to read using as a Primary Key in MySQL but have the disadvantages of i.e. not knowing the identifier until inserting to the database.
UUIDs help to build idempotent backend systems which is very important. However the UUID values are generated randomly and with clustered indexes the Page they are being saved will be also random with a uniform distribution resulting slow inserts. They influence read patterns too, resulting poor cache hit ratio. By InnoDB the Primary Keys are used as pointers in the secondary indexes increasing the size of the dataset.
Most of these problems can be solved:
- Pseudo-Random prefixed UUIDs and Mapping UUIDs to Integers can solve these problems.
- MySQL 8.0 introduced the UUID_TO_BIN(UUID(), true) and BIN_TO_UUID(..., true) functions with optionally shuffling the time parts to the top of a time based UUID.
- ramsey/uuid-doctrine provides a UuidBinaryOrderedTimeType Doctrine Type to handle indexes more efficiently
Mapping
We should write the database mapping of the Entities and Value Objects in a separate file (I.e. XML for Doctrine) in the Infrastructure to respect the Single Responsibility Principle and for the Separation of Concerns.
Validation
Encapsulate the validation of Value Objects and Entities. If the context needs additional validation i.e. about the object as a whole or composition of objects then separate this validation to the context as a service.
I.e. validate an Email Value Object By validating its minimum and maximum length and the format in the Value Object.
If our User has a general "email" and a new "notificationEmail" property then reuse the Email Value Object and if we need additional validation then pass i.e a MX record service in the "changeNotificationEmail" method's attribute according to the Interface Segregation Principle to do the validation in the Entity method and to keep everything testable.
If the context of our Entity needs to validate the entire Entity as a whole for its own purpose (i.e. property relations) then separate this responsibility in a Validation service like in an Anemic Model except this concern does not belong to the Entity rather to the context.
Aggregates
An Aggregate is related Objects we wish to treat as a unit. A consistency boundary which cluster Entities and Value Objects. A single Entity without child Entities or Value Objects conforms an Aggregate by itself.
Any references from outside the Aggregate should only go to the Aggregate Root. The Aggregate Root ensures the integrity of the Aggregate as a whole.
The reference by identity is called Disconnected Domain Model which is an approach I recommend. An injected repository can be used for navigating the referenced Aggregate.
The Aggregate has its own and single Repository whether it holds many Entities and Value Objects or none. This way no one will save a sub-Entity by mistake causing an inconsistent state. The changes are performed atomically on the Aggregate.
Invariants
A rule that must be true before and after every method call on the Aggregate and must be transactionally consistent. I.e. count must match with the amount of elements.
We should struggle to create small Aggregates. Usually we can define the boundaries of the Aggregates based on real invariants if the Aggregate is not too big. Not every association is an Aggregate, only the real invariants matter.
In a case when a lot of child Object is expected i.e. Gallery and Image the two Object should be two separate Aggregates.
Transactions and Aggregates
Transactions are handled on Application level and we must persist no more than one Aggregate instance per transaction! If we would change multiple Aggretages in a single transaction it would create the requirement that they are stored in the same database.
If the Business logic is changing over time and a new Invariant is introduced between two Aggregates we have two options.
- We can refactor our code into a single Aggregate which is not always possible
i.e.:
- different Bounded Contexts
- performance issues
- etc. - We can get away with eventual consistency.
Eventual consistency
Keeping consistency in a distributed system can be complex, it depends on the concrete case. However achieving Eventual consistency between two Aggregates in the same application is not that bad.
If the following steps can fail due to a business condition and we need to compensate somehow the previous Aggregates. Then we need a ProcessManager Aggregate Root that handles the always valid state of the process. We may also need to present the situation to a user with one or more options.
If the following steps can only fail due to technical reasons then we can assume the Aggregates will become eventually consistent.
Domain Events
Events that related to Domain Changes.
- Useful for decoupling, extension
- None, one or more components care about them
- Can dispatched to local or remote Bounded Contexts
- Domain Events are immutable
- Fully initialized by the constructor
- Have public getter methods but have no public setter methods
- Their names should be represented as verbs in the past tense and by terms of the Ubiquitous language, usually driven from the Command that was executed
- minimum one property needed: the time when the Event happened
- include only values not whole Aggregates or Entities
It is a good practice to record events in the Aggregate when they happen and later release them when we are sure the command is handled. This way the Aggregate and the DomainEventPublisher wont be coupled, will stay testable and the Model will stay consistent.
Services
Application services
- to transform Scalar types (unknown types for the Domain) into Domain types and reverse
- to coordinate, orchestrate
- to transform commands from the outside world into Domain instructions by executing Domain Model operations
- to handle transactions
Domain services
- to implement meaningful Domain Concepts and Business Logic which does not fit in Entities or Value Objects
- to achieve Domain model isolation
- to operate only on Domain types
Infrastructure services
- to implement Infrastructural Concerns
i.e. sending emails, logging, persisting data
Application services vs Domain services
Domain services hold Domain Logic whereas Application services does not.
Domain services participate in the decision-making process whereas Application services orchestrate those decisions.
When not to extract logic to a domain service?
I.e. if we are calling two different methods of the same Domain service/object from an Application service, and we can freely re-arrange the order of the method calls, it’s a strong sign that there is no Business Logic in our Application service. The cyclomatic complexity is 1.
I.e. maybe there is an early pre-condition in the Application service which is also checked in the Domain service/object but it would cause an Exception. In this case the cyclomatic complexity is higher than 1, but the actual decision-making process stays in the Domain, and the Application can guide the client through the process in a much nicer way.
When to extract logic to a domain service?
I.e. maybe we are not implementing an early pre-condition on a Domain service/object method call and the following steps of the Application service depend on a condition about the result. This would be decision-making. For decision-making we should introduce a new Domain service which works with the produced Domain objects in a way that the following steps of the Application service can be done regardless of the decision i.e. saving a Domain object with the Repository.
DTO Assembler
Domain Objects should not be exposed. I.e. maybe templating needs data from the Domain Layer or needs data in a different shape than the Domain Layer Aggregates are. Transforming and reverse transforming Domain Objects to DTOs happen in the Application Layer in DTO Assemblers.
I.e. for presentation purposes a "Product" Aggregate has a "ProductAssembler" in the Application Layer which maps the appropriate properties. And there is a "ProductDto" class / abstraction in the Presentation Layer.
Command Pattern
There are several ways to implement the Application Layer but a Request DTO looks pretty much like a Command Object so we could apply the Command Pattern.
Command Object
It describes what the user wants to do.
Command Handler
It describes how we want to handle the Command Object.
Command Bus
Its job is to match a Command Object to a Command Handler.
Tactician is the most popular Command Bus in PHP at the time.
Middleware
Finding and executing the appropriate Command Handler for the Command Object is a Middlware. We can decorate this base Middleware with additional Middlewares. When we execute a command, it is passed through every Middleware, at least once.
I.e.:
- validating the Command Object
- handling database transactions
- logging
- error handling
- queuing additional Command Objects
- handling user permissions
The Middlewares are executed in sequence, the order is configured when you setup the Command Bus and can’t be changed later. However, each Middleware can control when the next Middleware will start.
Controller
The controller has the single responsibility to wire things up.
- Passing the Request Object to a Form (i.e. the Symfony Form) for validation and Command Object creation
- Passing the Command Object to the Command Bus for handling and creating a single Response DTO
- Passing the Response DTO for the Templating and generating a Response Object
- Returning with the Response Object
Authentication, Authorization, Access Control
These are not part of the Domain unless the application is a security product.
Usually, Access Control is called before or after a domain operation is performed but not during.
User Session
- meant to hold the temporary state of a User's progress during an Application Task
- not a cache for the business logic
- not holding Domain Objects, at most DTOs.
I.e.
- A simple multi-step Form's state management which not involves Business Logic is an Application concern.
- A multi-request business use case can also manage its state in a Domain Service (which is a Domain concern) through a SessionProvider and Session interface of the Bounded Context.
Sources
These are just my notes and opinion about DDD based on
- my own experience
- the book Domain-Driven Design in PHP by Carlos Buenosvinos
- https://www.infoq.com/articles/microservices-aggregates-events-cqrs-part-1-richardson/
- https://www.percona.com/blog/2019/11/22/uuids-are-popular-but-bad-for-performance-lets-discuss/
- https://buildplease.com/pages/repositories-dto/
- https://enterprisecraftsmanship.com/posts/domain-vs-application-services/
- http://mysql.rjweb.org/doc.php/uuid
- https://cqrs.wordpress.com/documents/task-based-ui/
- http://balazblogspot.blogspot.com/2018/07/what-is-task-based-ui.html
- https://dev.to/barryosull/projection-building-blocks-what-youll-need-to-build-projections--5g1n
- https://medium.com/@sderosiaux/cqrs-what-why-how-945543482313
- the documentation of the listed technologies
- online discussions on the topic
I highly recommend buying the DDD book and reviewing the great examples and the whole topic in detail.